





Table of Contents
- Overview
- Setup
- Windows
- Linux
- OSX
- OpenCV Basics
- Getting Started
- Takeaways
Overview
You might have wondered how it is that your favorite social networking application can recognize you and your friends’ faces when you tag them in a photo. Maybe like Harry Potter, a mysterious letter arrived at your doorstep on your birthday; only this letter wasn’t an invitation to the esteemed Hogwarts Academy of Wizardry and Witchcraft, it was a picture of your license plate as you sped through an intersection. A fast- growing segment of artificial intelligence known as computer vision is responsible for both scenarios, as well as a host of other applications you will likely become familiar with in the near future.
The applications of computer vision are endless, both in utility and technical impressiveness, and if you haven’t already, it’s about time you began to witness the power that modern computing technology affords you. The time for painstakingly plodding a path through the dense mathematical forest of how exactly your phone can add funds to your bank account simply by taking a picture of your check has come and gone. Instead, let’s quickly cover only the basic yak-shaving required to spark your interest in how to get from zero to sixty, without the ticket to match.
Setup
The tool of choice to foray into how to see the world like a robot is OpenCV. This Python module is a virtual Swiss Army knife that will outfit our computers with bionic abilities. To do so however, we must first overcome setup and installation, which has become much easier than in years past. Depending on your machine and operating system, it should not take an average user with a novice to intermediate level of coding experience any more than 30 minutes, but if there are complications that your computer can’t stomach at first, be patient and in under an hour it will be worth it.
Windows
A few prerequisites to installing OpenCV are Matplotlib, SciPy, and NumPy. Downloading and installing the binary distributions of SciPy and NumPy, and Matplotlib from the source are the way to go. The installations of OpenCV change with the regularity you would expect from maintaining a large codebase, so check for the latest download instructions on the OpenCV website. Any other prerequisites that your system needs will be asked for during the setup process.
Linux
Most distributions of Linux will have NumPy preinstalled, but for the latest versions of both SciPy and NumPy, using a package manager like apt-get should be the easiest route. As far as OpenCV, the path of least resistance is to consult with the well-maintaind OpenCV Docs. This resource will walk you through the installation, as well as certain caveats and common troubleshooting gripes.
OSX
If you have OSX 10.7 and above, NumPy and SciPy should come preinstalled. All of the main sources mentioned above will cover prereqs, and as for OpenCV itself, Homebrew is the most convenient solution. If you don’t have it installed already, head over to the Homebrew (brew.sh) package manager. In most cases, once brew is installed, the instructions boil down to these basic commands: brew doctor , followed by, brew install opencv , or in error-prone cases, brew install opencv — env=std . In some instances, you may be asked by Homebrew to update a PYTHONPATH, which may involve opening the new (or existing) .bash_profile file in the text editor of your choice, and saving export PYTHONPATH=/usr/local/lib/python2.7/sitepackages:$ PYTHONPATH , or something like that there.
Patiently await the downloads and you should soon have everything installed! Check your installation by launching your Python interpreter with an import cv2 command, and there should be no error messages.
OpenCV Basics
The very basic gist behind OpenCV, along with NumPy, is that they are using multi-dimensional arrays to represent the pixels, the basic building blocks of digital images. If an image resolution is 200 by 300, it would contain 60,000 pixels, each of varying intensities along the RGB scale. You may have seen the RGB triple expressed similar to this (255,0,0) when dealing with a digital color palette from graphic design software or online image editor. Each pixel is assigned like this, and together they form an image, which can be represented as an entire matrix. This matrix of RGB tuples is what OpenCV is good at manipulating.
For this project, we’re going to examine some of the features that, when combined, can lead to some really interesting applications right out of the box. I’d like to see how accurately I can measure the size of some arbitrary objects in a photo.
Getting Started
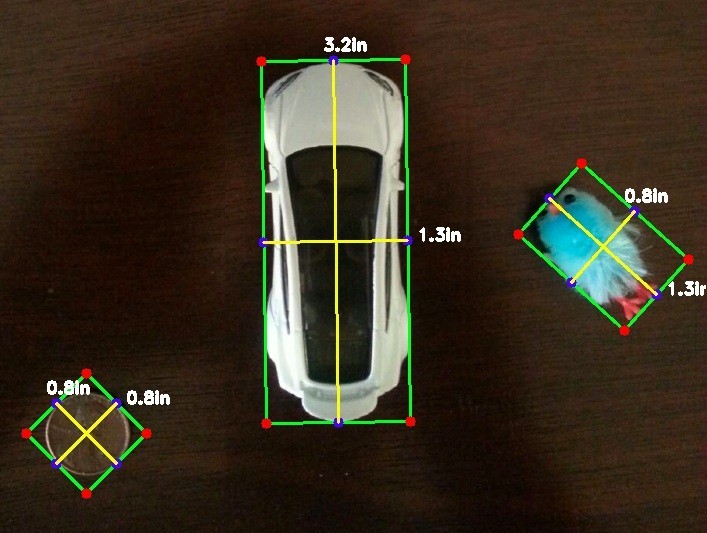
Since my son left them on the floor, and I stepped on them, I’ve taken a picture of his Hotwheels Tesla car, and a little birdie thing. To make this experiment more straightforward, I’ve added a reference object (a penny), whose size we already know in the image as well. From this reference object and the resulting pixel_to_size ratio, we’ll determine the sizes of other objects in the image.
![]()
The basic setup is to be able to run our script from the command line by feeding it the desired image, then it finds the object or objects of interest in the image, bounds them with a rectangle, measures the width and height of the images, along with some visible guides, and displays the output, right to our screen. You may need to pip install imutils or easy_install imutils, which is a package that makes manipulating images with OpenCV and Python even more robust.
Name a file thesizer.py, and input this code:
from scipy.spatial import distance as dist
from imutils import perspective
from imutils import contours
import numpy as np
import argparse
import imutils
import cv2
# construct the argument and parse command line input
aparse = argparse.ArgumentParser()
aparse.add_argument("--image", required=True,help="image p
ath")
aparse.add_argument("--width", type=float, required=True,h
elp="width of far left object (inches)")
args = vars(aparse.parse_args())
# load the image, convert it to grayscale, and blur it a b
it
image = cv2.imread(args["image"])
gray = cv2.cvtColor(image, cv2.COLOR_BGR2GRAY)
gray = cv2.GaussianBlur(gray, (7, 7), 0)
We first create a way to let the script know which image we want to use. This is done using the argparse module. We tell it that we are inputting an image, followed by our reference width. I’ve used a penny for our reference width, and Wikipedia tells me that our 16th president, Abraham Lincoln’s copper bust, measures 0.75 inches across. When we finally run the script on the command line, we’ll use this format: python thesizer.py –image hotwheel.png –width 0.75 . This argument parser is quite reusable, especially for future machine learning projects that you might encounter.
# perform edge detection + dilation + erosion to close gap
s bt edges
edge_detect = cv2.Canny(gray, 15, 100) #play w/min and max
values to finetune edges (2nd n 3rd params)
edge_detect = cv2.dilate(edge_detect, None, iterations=1)
edge_detect = cv2.erode(edge_detect, None, iterations=1)
Edge detection, dilation, and erosion are methods that will no doubt pop up on most image manipulation/computer vision tasks. A great habit to begin mastering and crafting your own projects, is to dive into the more important methods used under the hood by studying the source documentation. Edge detection can be a complex subject if you want it to be. It’s one of the building blocks of computer vision, and should raise your curiosity if you like looking under the hood to find out how things work. The OpenCV docs, while definitely having an old-school vibe, are actually pretty detailed and informative. What we’ve done with the gray variable was to turn our image grayish, helping define the edges and contours. Now, the Canny method, named after its founder John F. Canny, uses a combination of noise reduction and something called intensity gradients to determine what are continuous edges of an object, and what is probably not. If you want to see what our poor man’s Terminator sees at this point, you could just display edge_detect by adding cv2.imshow(‘Edges’,edge_detect) . It would look something like this:
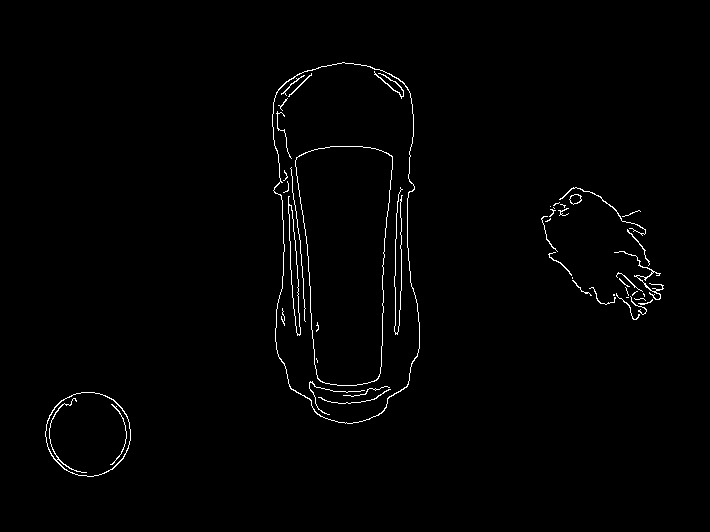
If you use your imagination a bit, you can start to see how Cyberdyne Systems was able to have the T1000 identify motorcycles, leather jackets, and shotguns in the future.
# find contours in the edge map
cntours = cv2.findContours(edge_detect.copy(), cv2.RETR_EX
TERNAL, cv2.CHAIN_APPROX_SIMPLE)
cntours = imutils.grab_contours(cntours)
# sort contours left-to-right
(cntours, _) = contours.sort_contours(cntours)
pixel_to_size = None
# function for finding the midpoint
def mdpt(A, B):
return ((A[0] + B[0]) * 0.5, (A[1] + B[1]) * 0.5)
The findCountours method further identifies what we would consider contours of various whole objects in our image. We sort them left-toright, starting with our reference penny. Knowing that the penny goes first, we can use our pixel_to_size ratio to find out the sizes of the other objects. We’ve just initialized the penny ratio here, and we’ll use it later. Lastly, we create a function to find the middle of the object lines that we’ll draw later, so keep that in mind.
# loop over the contours individually
for c in cntours:
if cv2.contourArea(c) < 100: #ignore/fly through cont
ours that are not big enough
continue
# compute the rotated bounding box of the contour; sho
uld handle cv2 or cv3..
orig = image.copy()
bbox = cv2.minAreaRect(c)
bbox = cv2.cv.boxPoints(bbox) if imutils.is_cv2() else
cv2.boxPoints(bbox)
bbox = np.array(bbox, dtype="int")
# order the contours and draw bounding box
bbox = perspective.order_points(bbox)
cv2.drawContours(orig, [bbox.astype("int")], -1, (0, 2
55, 0), 2)
Everything else in this script runs under this for loop. Our contours now define what we think to be the isolated objects within the image. Now that that’s complete, we make sure that only contours/objects that have an area larger than 100px will stay to be measured. We define bounding boxes as rectangles that will fit over the objects, and turn them into Numpy arrays. In the last step we draw a green bounding box. Note that OpenCV reverses the order of Red, Green, and Blue, so Blue is the first number in the tuple, followed by Green, and Red.
Basically, all that’s left is to draw our lines and bounding points, add midpoints, and measure lengths.
# loop over the original points in bbox and draw them; 5px
red dots
for (x, y) in bbox:
cv2.circle(orig, (int(x), int(y)), 5, (0, 0, 255),
-1)
# unpack the ordered bounding bbox; find midpoints
(tl, tr, br, bl) = bbox
(tltrX, tltrY) = mdpt(tl, tr)
(blbrX, blbrY) = mdpt(bl, br)
(tlblX, tlblY) = mdpt(tl, bl)
(trbrX, trbrY) = mdpt(tr, br)
Here’s where we use our midpoint function, mdpt . From our four bounding box points that enclose our object, we’re looking for half-way between each line. You see how easy it is to draw circles for our bounding box points, by using the cv2.circle() command. Without cheating, can you tell what color I’ve made them? If you guessed Blue… you’re wrong! Yep, Red – There’s that order reversal that OpenCV likes to use. Red dots, 5px big. When you run the code yourself, change some of these parameters to see how it alters what we’re drawing or how the bounding boxes might get thrown off by poor countours, etc.
# draw the mdpts on the image (blue);lines between the mdp
ts (yellow)
cv2.circle(orig, (int(tltrX), int(tltrY)), 5, (255, 0,
0), -1)
cv2.circle(orig, (int(blbrX), int(blbrY)), 5, (255, 0,
0), -1)
cv2.circle(orig, (int(tlblX), int(tlblY)), 5, (255, 0,
0), -1)
cv2.circle(orig, (int(trbrX), int(trbrY)), 5, (255, 0,
0), -1)
cv2.line(orig, (int(tltrX), int(tltrY)), (int(blbrX),
int(blbrY)),(0, 255, 255), 2)
cv2.line(orig, (int(tlblX), int(tlblY)), (int(trbrX),
int(trbrY)),(0, 255, 255), 2)
# compute the Euclidean distances between the mdpts
dA = dist.euclidean((tltrX, tltrY), (blbrX, blbrY))
dB = dist.euclidean((tlblX, tlblY), (trbrX, trbrY))
Not much going on here except drawing blue midpoints of lines, 5px big. dA and dB are a bit more interesting, because we are computing the distance between bounding box points. We did this with the euclidean() method of the dist object that we imported from the SciPy library at the start of our script.
On to the finale:
# use pixel_to_size ratio to compute object size
if pixel_to_size is None:
pixel_to_size = dB / args["width"]
distA = dA / pixel_to_size
distB = dB / pixel_to_size
# draw the object sizes on the image
cv2.putText(orig, "{:.1f}in".format(distA),
(int(tltrX - 10), int(tltrY - 10)), cv2.FONT_HERSH
EY_DUPLEX,0.55, (255, 255, 255), 2)
cv2.putText(orig, "{:.1f}in".format(distB),
(int(trbrX + 10), int(trbrY)), cv2.FONT_HERSHEY_DU
PLEX,0.55, (255, 255, 255), 2)
# show the output image
cv2.imshow("Image", orig)
cv2.waitKey(0)
Here’s where the magic happens. We can now employ our penny ratio to find the size of the other objects. All we need is to use one line divided by our ratio, and we know how long and wide our object is. It’s like using a map scale to convert an inch into a mile. Now we superimpose the distance text over our original image (which is actually a copy of our original image). I’ve rounded this number to one decimal place, so that would explain why our result shows our penny as having a height and width of 0.8 inches. Rest assured skeptics, it has rounded up from a perfect 0.75 inches; of course, you should change the accuracy to two decimal places yourself, just to make sure. Our last two lines are commands to display our image and rotate through the drawn bounding boxes on any key press.
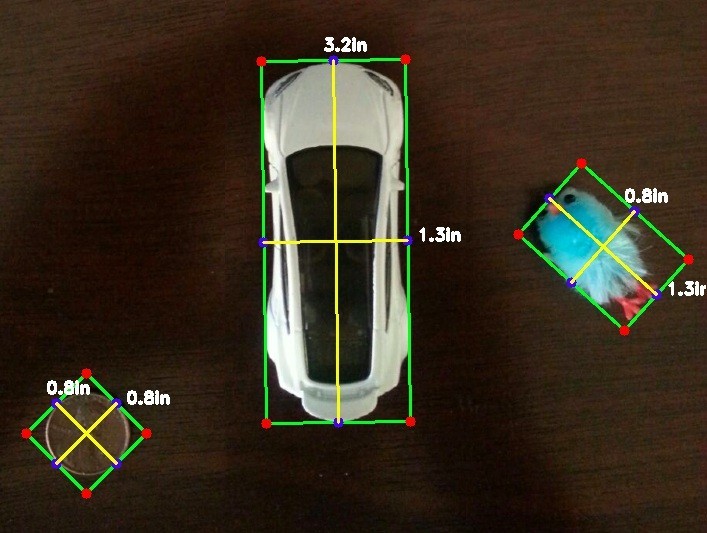
Takeaways
I told you we would dive right in. You may want to try snapping a similar photo of your own and tinkering with many of these reusable code snippets. Of particular interest are these methods, that will popup again and again in your future computer vision projects:
- cv2.cvtColor() for graying images
- cv2.Canny() for edge detection
- cv2.findContours() for whole object detection
- cv2.boxPoints() for creating bounding boxes (CV3)
- cv2.circle() and cv2.line() for drawing shapes
- cv2.putText() for writing text over images
As you can see, the world of computer vision is unlimited in scope and power, and OpenCV unlocks the ability to use machine learning to perform tasks that have traditionally been laborious and error-prone for humans to do en masse, like detect solar panel square footage for entire zip codes, or define tin rooftops in African villages. We encourage you to empower yourselves by diving in and experimenting.